
论文:meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples, ICLR 2020
meta-Dataset 提出的初衷:mini-ImageNet、tiered-ImageNet 等数据集虽然在训练和验证时使用的类别没有交集,但是从外观上看,验证时使用的类别在很大程度上与训练时使用的类相似。导致验证过程仍可 reuse 训练时学习到的 feature embedding。但是,这样就无法验证 model 是否真的能从验证集的 support set中 进行学习。因此,meta-Datase t融合了多种来源的数据集,想要在该数据集上表现良好,就需要在训练时学习多元信息,并在验证时将其快速 adapt 到完全不同的任务上。
数据来源:meta-Dataset 由 10个数据集 抽取组成,其中包括自然图像数据集、手写字符及涂鸦数据集。FLUTE 又扩充了3个数据集,包括MNIST,CIFAR-10和CIFAR-100,扩充数据集见 CNAPs。
- ILSVRC-2012(ImageNet子集)
- Omniglot
- FGVC-Aircraft
- CUB-200-2011 (Birds)
- Describable Textures (DTD)
- Quick Draw
- FGVCx Fungi
- VGG Flower
- German Traffic Sign Recognition Benchmark (GTSRB)
- Common Objects in Context (COCO)
- MNIST*
- CIFAR-10*
- CIFAR-100*
适用任务:Few-shot Image Classification
数据集使用说明:
- meta-Dataset 中 Traffic Sign (GTSRB) 和 COCO 数据集不参与训练,仅用于验证或测试。其余的 8 个数据集大致按照 70% / 15% / 15% 的比例划分训练 / 验证 / 测试集。
- 作者提供了每个数据集的 train/val/test 划分文件:train/va/test splits,其中没有 ILSVRC-2012 和 Omniglot 的划分,因为 ILSVRC-2012 具有层级结构,作者根据 root class 划分了训练/验证/测试,Omniglot 原本就划分了训练和测试,作者依照了原始划分,具体怎么做的请继续往下看。
下载方式:建议参考 meta-dataset github,我这里对个人的处理过程进行了详细记录。
meta-Dataset 需要分别下载 10 个数据集,再经过一定的处理将他们转换为同一种组织格式(每个数据类别对应一个TFRecord)。给出的转换脚本以 ILSVRC-2012 为例:
进入 meta-dataset 根目录下,执行转换代码:
其中:
- ilsvrc_2012_data_root 为你的数据存放路径,对不同的数据集做转换时要进行修改
- splits_root 为 文件的存放路径,除了 ilsvrc_2012 和 omniglot 外,其他 8 个数据集都会生成一个 splits 文件,用于划分 train/val/test 类别。如果想要使用作者提供的标准划分,就将 splits_root 设置为 ,否则当程序找不到需要的 split 文件时,就会自动随机划分数据并生成 split 文件(P.S. 如果不修改源代码,随机生成的结果其实和标准数据划分是一致的,因为作者已经固定的随机数种子,可以通过对照 标准数据划分 来确认一下)
- records_root 为转换后的数据存放路径
查看数据转换代码: 中所有数据集的 Converter 均继承自 DatasetConverter 类,其初始化参数 用于指定数据集的 split 文件。若提供了数据集 split json 文件,则会通过 方法读取,否则会通过 方法创建。提供 的接口作者给出了,但是并没有对应实现,可能是因为只要不修改随机数种子,每个人随机生成的 json 文件其实就是标准划分吧。

文件示例:
比如我这里使用作者的标准划分,转换后的数据存放在 :
(所有数据集的转换脚本都是一样的,只要修改上面的参数即可,后面就不再重复了)
出现这条信息,就说明开始转换了:
官方给出的数据集的处理代码基于 Tensorflow 2,因此需要安装 Tensorflow 2,按照官方给出的教程安装即可,但是要注意安装 Tensorflow 2 的系统要求。
- Python 版本 3.6 ~ 3.9,若 Python=3.8,则需要 Tensorflow >= 2.2,若 Python=3.9,则需要 Tensorflow >= 2.5
- pip 版本 >= 19.0
- Ubuntu 版本 >= 16.04
我这里是 Ubuntu16.04 系统,在 Conda 环境下进行安装,因此下面只列出我的安装过程:
step1:检查 Conda 环境下的 Python 和 pip 版本,刚好环境 ok,可以直接进入下一步
step2:安装 Tensorflow pip 包
可以看到成功返回了张量,安装成功~
1. ILSVRC-2012
需要下载 ILSVRC2012,可以参考:ILSVRC-2012 的详细下载方式,我们需要下载的是 Training images (Task 1 & 2),对应压缩包名称为 (138GB)。
关于 train/val/test 划分方式:ILSVRC-2012 共包含1000个类别,meta-Dataset 仅使用了 ILSVRC-2012 的 training set 部分,并基于 training set 划分训练、验证和测试集。训练/验证/测试按照类别数量划分为 712/158/130。从 论文 中可以看到,作者选择 和 作为验证集和测试集的 root 结点,其余的都作为训练集。因此,训练集包含 712 个类别,验证集包含 158 个,测试集包含 130 个。
在 数据转换过程 中,meta-Dataset 会将 ILSVRC-2012 数据中与其他数据集重复的样本跳过,这样就能保证使用其他数据集作为 test set 时,不会已经见过该样本。其中 ILSVRC-2012 与 CUB-200-2011重复 43 张,与 Caltech-101 重复 92 张,与 Caltech-256 重复 286 张。注意:Caltech-101 和 Caltech-256 不包含在 meta-Dataset 中,但作者还是去掉了,应该是以防其他工作需要用到吧,未雨绸缪了。

ILSVRC-2012 的转换代码: 作者在注释中写的很清楚,这里仅使用了 ImageNet 数据集的 training set 部分,并且与Caltech101、Caltech256、CUBirds这三个数据集有交集的数据在转换过程中都会被 skip 掉。
step 1:准备数据(解压过程大约需要30分钟)
数据下载好之后解压:
在文件夹 下面包含了1000个子压缩包 ,继续对每个子压缩包进行解压。在当前目录下创建脚本文件:
直接复制粘贴下面代码内容:
执行脚本文件进行解压:
下载 wordnet.is_a.txt 和 words.txt 两个文件,放在 目录下。
step 2:转换数据
进入 meta-dataset 根目录下,执行转换代码(改为),最终转换完成的文件在 下,包含:
- 1000 个 文件,编号为 0~999
- 文件,关于数据集的一些信息
- 文件
2. Omniglot
meta-Dataset 只需要使用 Omniglot 中的 images_background.zip 和 images_evaluation.zip 两个文件。Omniglot 的下载可以参考 Omniglot 的详细下载方式。
Omniglot 的类别划分为了两级,第一级为 ,第二级为 。meta-Dataset 使用了 Omniglot 的原始划分方式,即 background 作为训练集,evaluation 作为测试集,不同的是,Omniglot 没有设置验证集,因此 meta-Dataset 从训练集中划分出了 5 个最小的 alphabet 集合作为验证集,因此实际上的训练集只有 25 个 alphabet。
step1:准备数据
下载 images_background.zip 和 images_evaluation.zip,保存在文件夹 下,解压两个数据压缩包到当前文件夹。
step2:转换数据
进入 meta-dataset 根目录下,执行转换代码(改为),最终转换完成的文件在 下,包含:
- 1623 个 文件,编号为 0~1622
- 文件
3. FGVC-Aircraft
step1:准备数据
下载 fgvc-aircraft-2013b.tar.gz 到目录 ,即可在当前目录下解压:
step2:转换数据
进入 meta-dataset 根目录下,执行转换代码(改为),最终转换完成的文件在 下,包含:
- 100 个 文件,编号为 0~99
- 文件
4. CUB-200-2011 (Birds)
meta-Dataset 使用 CUB-200-2011 数据集的分类部分数据 ,即下载 Images and annotations (1.1 GB)。关于 CUB-200-2011 的详细内容解释参考:CUB-200-2011 的使用与下载。
step1:准备数据
下载数据到目录 ,即可在当前目录下解压:
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 200 个 文件,编号为 0~199
- 文件
5. Describable Textures (DTD)
step1:准备数据
下载 dtd-r1.0.1.tar.gz 到目录 ,即可在当前目录下解压:
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 47 个 文件,编号为 0~46
- 文件
6. Quick Draw
step1:准备数据
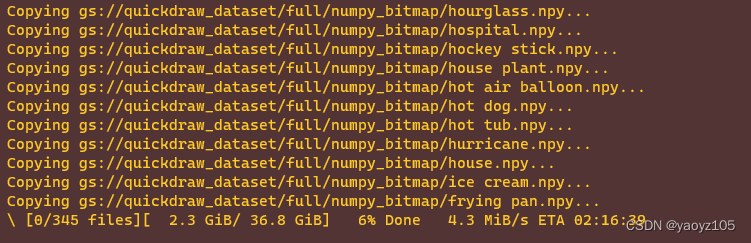
需要从 Google Cloud 下载 345 个 文件,直接手动下载太麻烦,可以安装 gsutil 工具来下载。我这里在服务器上直接下载,首先要保证当前环境有 Python,执行如下:
最后一行显示了下载进度:
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 345 个 文件,编号为 0~344
- 文件
7. FGVCx Fungi
step1:准备数据
下载 fungi_train_val.tgz 和 train_val_annotations.tgz 到目录 ,即可在当前目录下解压:
解压出的文件包含一个 文件夹和 、 文件。
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 1394 个 文件,编号为 0~1393
- 文件
8. VGG Flower
step1:准备数据
下载 102flowers.tgz 和 imagelabels.mat 到目录 ,即可在当前目录下解压:
解压完成仅包含一个 文件夹,包含了所有图像。
P.S. 注意 imagelabels.mat 由于特殊后缀,浏览器可能不会直接解析并下载,此时可以右键选择 “将链接另存为” 或者直接在命令行输入:
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 102 个 文件,编号为 0~101
- 文件
9. German Traffic Sign Recognition Benchmark (GTSRB)
step1:准备数据
下载 GTSRB_Final_Training_Images.zip 到目录 (备用链接 website),即可在当前目录下解压:
解压完成后得到一个 文件夹。
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 43 个 文件,编号为 0~42
- 文件
P.S. 转换代码的 指定到 GTSRB 文件夹下。
10. Common Objects in Context (COCO)
step1:准备数据
meta-Dataset 使用 MSCOCO 数据集的 training 部分数据,在 COCO官网 下载 train2017.zip 和 annotations_trainval2017.zip 到目录 。
P.S. 使用 gsutil 下载的方式目前(2022-07-04)不可行,好像是因为 bucket 不可用,因此会报错:
不过没准呢,说不定你看到的时候就可以下载了,可以按照下面的方式下载:
解压数据:
step2:转换数据
进入 meta-dataset 根目录下执行转换代码(改为),最终转换完成的文件在 下,包含:
- 80 个 文件,编号为 0~79
- 文件
FLUTE 在 meta-Dataset 基础上又扩充了 3 个测试数据集,分别是 MNIST,CIFAR-10 和 CIFAR-100,扩充数据集见 CNAPs。
首先仍然进入存放 meta-dataset 10 个数据集的根目录下。
11. MNIST & CIFAR10 & CIFAR100
step1:准备数据
step2:转换数据
cd 进入 目录,执行:
处理完毕后,会在 RECORDS 目录下分别生成 MNIST,CIFAR-10 和 CIFAR-100 的数据文件夹。
3.1节是关于数据集组成的介绍,在前面的数据集处理部分已经介绍过了。可以看到关键词就是 multiple existing datasets,也就是来源数据包括多个数据集,为的是探究 meta-learner 是否能从来源各异的数据中学习一些东西,并且也提供了一个更有挑战性的模型泛化任务。最后作者说更详细的信息在附录里。

紧接着介绍了meta-Dataset 是如何使用这些数据的。在训练时,每个 episode 数据都来自不同的数据集(随机挑选),且每个 episode 的数据仅来自一个数据集。此外,Traffic Signs 和 MSCOCO 数据集不用于 training,仅用于 evaluation。其余 8 个数据集用于训练阶段,且都划分了训练/验证/测试集(比例大致为 70:15:15),划分文件见:splits file。

3.1节特别介绍了 ImageNet 和 Omniglot
附录(Appendix)里介绍了几块内容:
- 作者建议研究人员如果使用 meta-Dataset,在PO出你的研究时,最好包含的一些结果。
- meta-Dataset 是如何 sample 数据的。
- 10 个来源数据集的额外信息。
- 一些超参数。
- 主要的实验结果和论文中 rank 指标是如何计算的。
- 对于不同 ways 和 shots 设置下,模型 performance 的分析结果
- 在所有(10个)数据集上训练和仅在 ILSVRC-2012 上训练的 effects
- 先进行 pre-training 再进行 meta-training 和直接 meta-training from scratch 的 effects
- meta-learning 和 inference-only 的 effects
- 其他分析